清尘
清尘
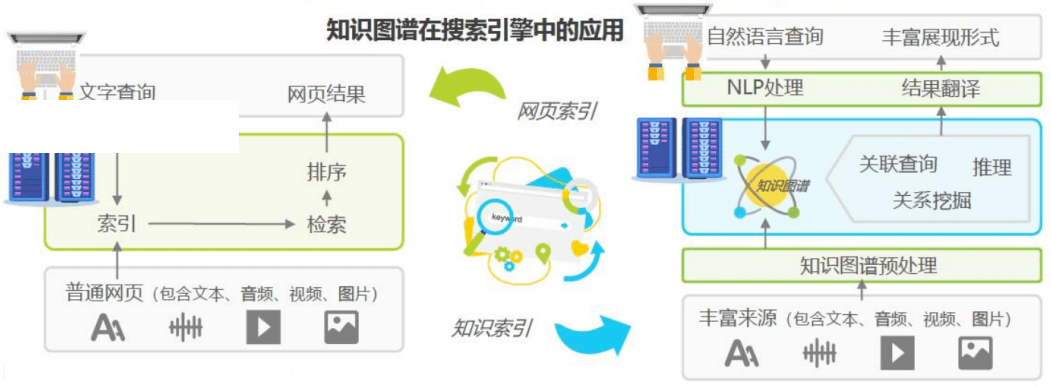
知识图谱
三元组
- 实体 - 关系 - 实体
案例: 周杰伦-妻子-昆凌 - 实体 - 属性 - 属性值
案例:周杰伦-年龄-46
实体与其他的区别就在于,实体拥有属性、标签、和其他实体的关系。当然也可用根据实际的场景,去定义实体、属性、标签之间的区别和定义。
核心
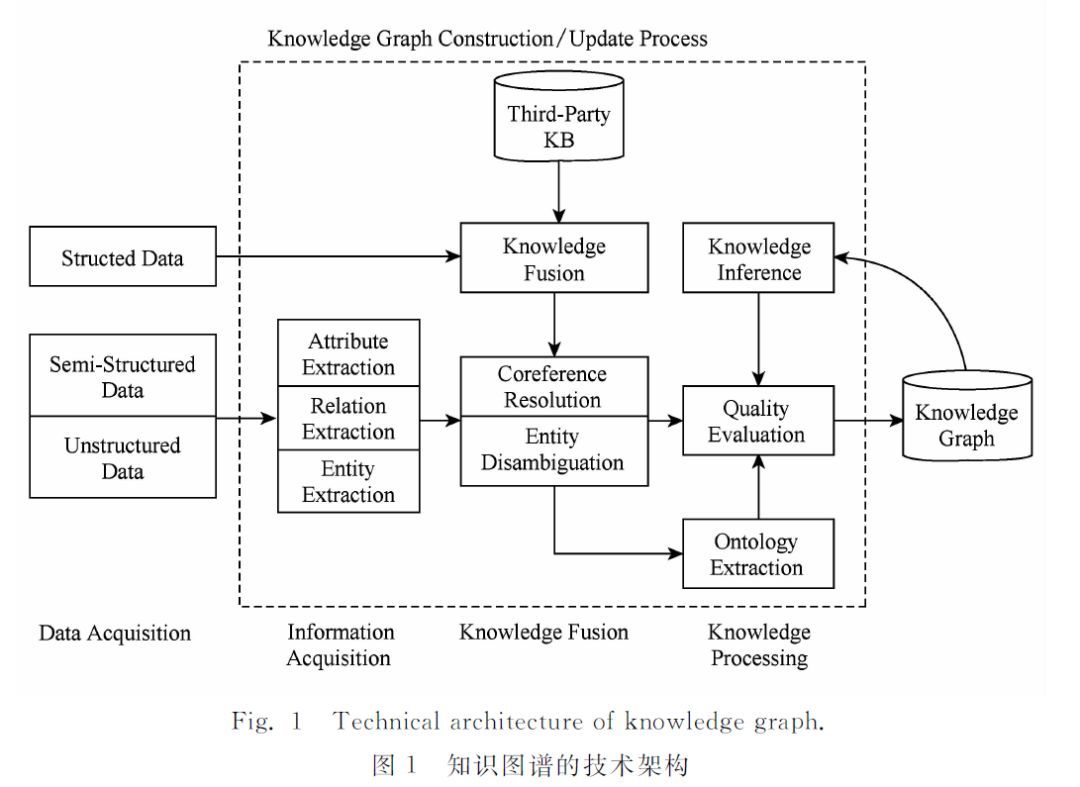
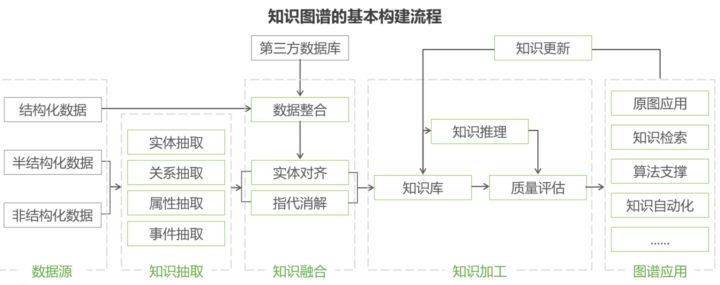
知识抽取
实体抽取
又称命名实体识别(named entity recognition,NER)
实体定义/节点定义
题目
{
"id": "thisisatestqid",# uuid
"major": "英语",# 学科 枚举:英语、数学...
"source": "教材",# 知识点来源 枚举 教材、教辅、用户上传、其他
"region": "地域", # 题目地域
"version": "人教版",# 教材版本 非必填 枚举值 译林、人教、外研社、新概念
"grade": 1,# 年级 1-9分别代表1-9年级,0代表通用
"volume": "上册",# 册数 上册\下册
"unit": 1,# 单元
"type": "单选题",# 知识点类型 单元知识点、单词/词组知识点
"sub_type": "选择题",# 知识点子类型
"score": 1.5,# 题目默认分值
"sq_number": 0,# 题目小题数
"difficulty": 0.1,# 题目难度
"q_content": "",# 题目内容
"q_question": ["问题1"],# 问题列表
"q_option": ["选项1", "选项2"],# 选项列表 内容是string格式的json字符串
"media_url": ["音频地址"],# 媒体文件列表
"audio_duration": [60],# 音频时长列表
"answer": ["答案"],# 答案列表
"answer_detail": ["答案详解"],# 答案详解
"feature": ["题目特征"]# 题目特征
}
未声明非必填的属性均为必填项
知识点
{
"id": "thisisatestkid",# uuid
"major": "英语",# 学科 枚举:英语、数学...
"source": "教材",# 知识点来源 枚举 教材、教辅、用户上传、其他
"version": "人教版",# 教材版本 非必填 枚举值 译林、人教、外研社、新概念
"grade": 1,# 年级 1-9分别代表1-9年级,0代表通用
"volume": "上册",# 册数 上册\下册
"unit": 1,# 单元
"type": "知识点类型",# 知识点类型 单元知识点、单词/词组知识点
"name": "单词1",# 知识点名称
"content": "单词1内容"# 知识点内容 长文本
}
未声明非必填的属性均为必填项
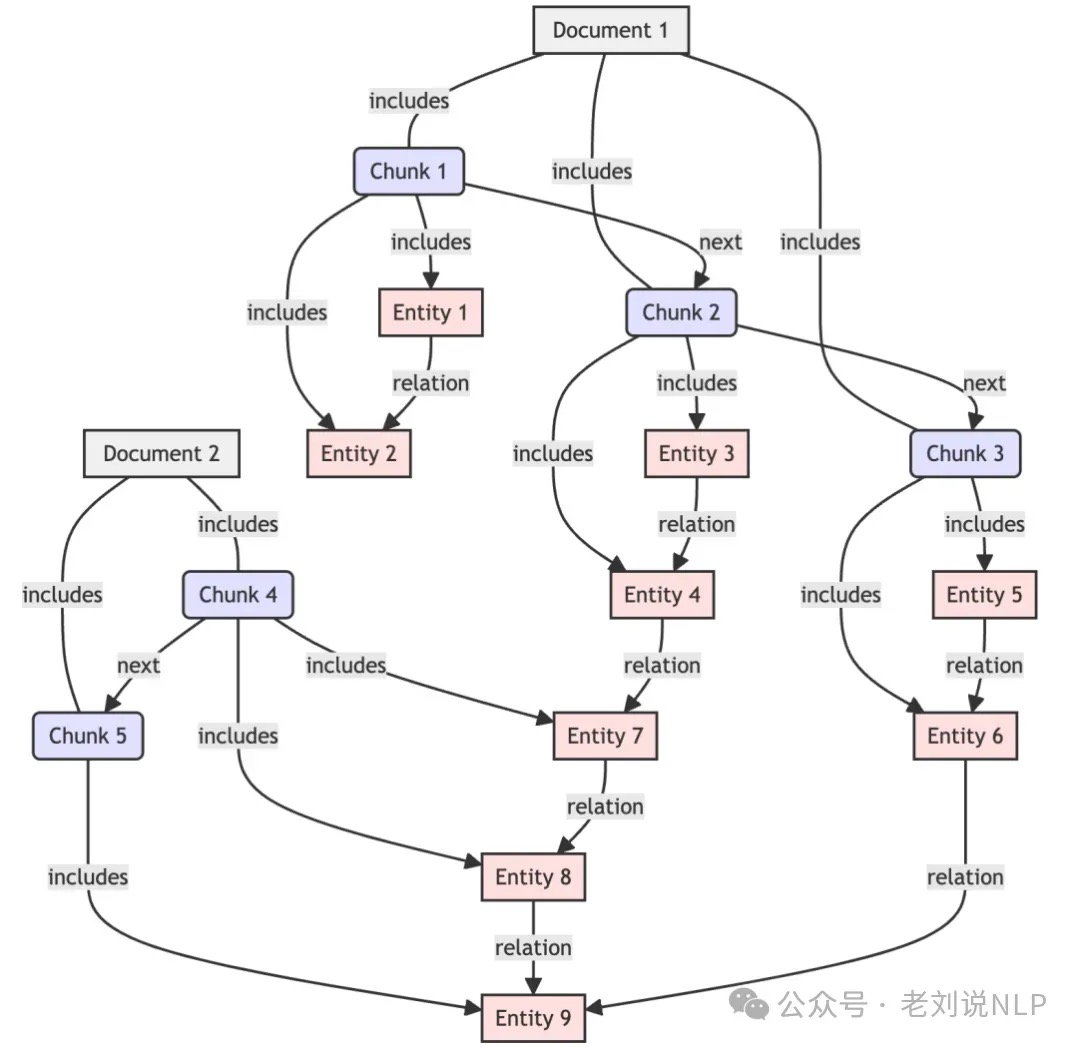
文档
document:
id: uuid # 唯一标识uuid
name: string # 文档名称
grade: int # 年级 非必填 枚举值:1-9,分别代表1-9年级
unit: int # 单元 非必填
major: string # 学科 非必填 枚举:英语、数学、语文、科学、物理、化学、生物、历史、政治、地理
source: string # 文档来源 课本、教辅、试卷、网页、其他
content: text # 文档概述 非必填 (讨论是否需要)
other: string # 其他属性 非必填
未声明非必填的属性均为必填项
文档块
chunk:
id: uuid # 唯一标识uuid
from: uuid # 文档id
content: text # 文档块内容
other: string # 其他属性 非必填
未声明非必填的属性均为必填项
图解:
- 知识点通过模型抽取
- 题目(部分通过模型抽取)、文档和文档块为结构数据
关系抽取
关系定义/边定义
- 题目和知识点的关系通过模型提取
- 题目和题目的关系通过结构化(辅)和模型提取(主)
- 知识点和知识点的关系通过模型提取(主)和结构化(辅)
edge:
type: string # 边类型 示例:考察、属于、知道、创造...
start: nodeId # 开始节点
end: nodeId # 结束节点
other: xxx # 边的附加属性 非必填
score: float # 关系的强弱程度
...
未声明非必填的属性均为必填项
附
抽取步骤(以课本为例):
- 课本读取、单元划分
- 按照单元抽取知识点、题目、关系
- 抽取完成清洗后以单元为最小簇搭建关系
- 重复此循环
抽取提示词示例:
prompt = """ ## 目标 从英语学科教材、教辅资料及试题文本等文本块中提取知识点、题目实体及其关联关系,构建结构化知识图谱。 ### 实体定义 - 实体类型:知识点 - 实体属性: - id: 知识点ID(k1、k2...)必填 - type: 知识点类型 枚举如下:{knowledge_point_types} 必填 - name: 知识点名称(如"一般现在时"、"定语从句"、"词汇名称")必填且唯一 - content: 知识点详细说明(长文本,需整合原文描述)必填 - 实体类型:题目 - 实体属性: - id: 题目ID(如"q1"、"q2")必填 - type: 题目类型 枚举如下:{question_types} 必填 - score: 题目难度 0-1的浮点数 (AI评估难度分数) 必填 - content: 题目内容 长文本,需整合原文描述 必填 - answer: 题目答案 必填 - answer_detail: 题目解析 长文本,需整合原文描述 非必填 - option_list: 答案选项列表 (如果题目是选择题、多选题) 非必填 - option_a: 选项A - option_b: 选项B - option_c: 选项C - option_d: 选项D ... ### 关系定义 - 边类型:枚举如下:必填 - 题目与题目之间:{question_to_question_relations} - 题目与知识点之间:{question_to_knowledge_relations} - 知识点与知识点之间:{knowledge_to_knowledge_relations} - 边属性: - score: 关系强度(0.1-1.0,AI评估关联程度)必填 - start: 源实体ID 必填 - end: 目标实体ID 必填 ### 提取步骤 1. 实体提取: - 识别所有知识点实体,JSON格式: {{"knowledge":{{"id":"知识点id","type":"知识点类型","name":"知识点名称","content":"知识点内容"}}}} - 识别所有题目实体,JSON格式: {{"question":{{"id":"题目id","type":"题目类型","score":"题目难度系数","content":"题目内容","answer":"题目答案","answer_detail":"题目解析","option_list":{{"option_a":"A: 选项","option_b":"B: 选项","option_c":"C: 选项"}}}}}} 2. 关系提取: - 识别实体间显式关系,格式: {{"relationship":{{"type":"实体之间关系类型","start":"源实体id","end":"目标实体id","score":float 0-1}}}} 3. 输出格式要求: - 每个实体或关系占一行JSON格式 - 整体生成的格式符合jsonl格式 - 生成完毕后最终标记为:**** ## 示例 输入文本: Unit Unit 1 Hello!知识点 一、认识人物。 Bobby 波比 Sam 山姆 二、单词。 1、hello 哈啰,你好 2、class 同学们 3、I 我 4、am 是 三、词组。 1、Good morning. 早上好。 2、my teacher 我的老师 3、my friend 我的朋友 4、Good afternoon 下午好 四、句型。<★英文中句子开头首字母要大写!> 1、Hi,I’m Bobby. 你好,我是波比。 2、Good morning,Miss Li. 早上好,李老师。 3、Hi,Yang Ling. 你好,杨玲。 五、单元知识点。 1、各时间段问好。 Good morning:指中午12 点之前。应答语同样是Good morning. 早上或上午问候时也可省略good,直接说“Morning.” Good afternoon:指12 点到18 点之间的时间段。应答语同样是Good afternoon. Good evening:18 点后到睡觉前。 这是人们在晚上见面时较正式的问候语,应答语同样可用Good evening. Good night. “晚安”, 用于睡觉前的问候。【night 指晚上9 点以后】 1. What's this? - It's a ______. (C) A. dogs B. cat's C. dog (解析:a 后面接可数名词单数,dog 是单数形式) 输出: {{"knowledge":{{"id":"k1","type":"单元知识点","name":"认识人物","content":"Bobby 波比 Sam 山姆"}}}} {{"knowledge":{{"id":"k2","type":"单词","name":"Bobby","content":"Bobby 波比 人名"}}}} {{"knowledge":{{"id":"k3","type":"单词","name":"Sam","content":"Sam 山姆 人名"}}}} {{"knowledge":{{"id":"k4","type":"单词","name":"hello","content":"hello 哈啰,你好"}}}} ... {{"question":{{"id":"q1","type":"单选题","score":"0.2","content":"What's this? - It's a ______.","answer":"C","answer_detail":"解析:a 后面接可数名词单数,dog 是单数形式","option_list":{{"option_a":"A: dogs","option_b":"B: cat's","option_c":"C: dog"}}}}}} ... {{"relationship":{{"type":"归类关系","start":"k1","end":"k2","score":1.0}}}} {{"relationship":{{"type":"归类关系","start":"k1","end":"k3","score":1.0}}}} ... **** ### 特殊规则 1. 内容字段需整合多来源描述,矛盾时以最新教材表述为准 2. 关系强度判定标准: - 1.0: 文本明确说明(如"直接考查") - 0.6-0.9: 隐含但强关联(如练习题涉及) - 0.1-0.5: 弱关联(如扩展阅读提及) 3. 文档中可能存在多种题型,也可能不包含题目,需根据题目内容判断 4. 每个实体或关系占一行JSON格式 5. 确保提取结果少而精,保证质量的前提下,尽可能多的提取实体和关系 ### 输入数据 Text: {input_text} 请开始提取:"""
知识融合
实体对齐
多源融合(类似多义词融合)
实体消歧
同一个单词,语境不同消歧
属性对齐
实体对齐后相关属性对齐
知识推理
模型训练
知识表示
简介: 将知识图谱中的实体,关系,属性等转化为向量,利用向量间的计算关系,反映实体间的关联性。
原理逻辑: 对于三元组(h, r, t),学习其向量表示lh lr lt 使其满足 lh + lr ≈ lt,即实体加上关系,应该接近另一个实体。
模型向量
图数据库
- Neo4J
- HugeGraph
Neo4J数据库比较好上手
附