 清尘
清尘
Stanford CS336 | Language Modeling from Scratch | 01
前言
Language Modeling from Scratch
大模型这块从23年开始断断续续的学都是工作涉及哪块就学哪块,没什么体系,准备跟着CS336学下来看看之前有没有漏学了哪些东西。
简述
第一节课前面大部分都是课程安排,最后讲了tokenizer。
讲为什么出现这门课,现在的landscape
Problem: researchers are becoming **disconnected** from the underlying technology.
8 years ago, researchers would implement and train their own models.
6 years ago, researchers would download a model (e.g., BERT) and fine-tune it.
Today, researchers just prompt a proprietary model (e.g., GPT-4/Claude/Gemini).
说的不就是我吗,碰到问题先改提示词再说!
Intuitions
培养直觉去找到哪些数据和模型架构决策会得到好的数据结果
这块还引用了SwiGLU,上帝来力~
We have extended the GLU family of layers and proposed their use in Transformer.
In a transfer-learning setup, the new variants seem to produce better perplexities for the de-noising objective used in pre-training, as well as better results on many downstream language-understanding tasks.
These architectures are simple to implement, and have no apparent computational drawbacks.
***We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.***
这整个讲座都是可执行代码好屌的,比ppt带劲多了
铭记这句话: have an obsessive need to understand how things work.
现在就是基于已经建设好的框架和模型去微调,却不知道原理。
事物从来不是瞬间就出现,都是由人、物、时间经过漫漫长路发展成现在这样的。
还记得我初高中说历史有什么好读的,谁知道是不是真这样的。现在发现历史的重要性啊!
有5个作业:基础、系统、缩放法则、数据、对齐

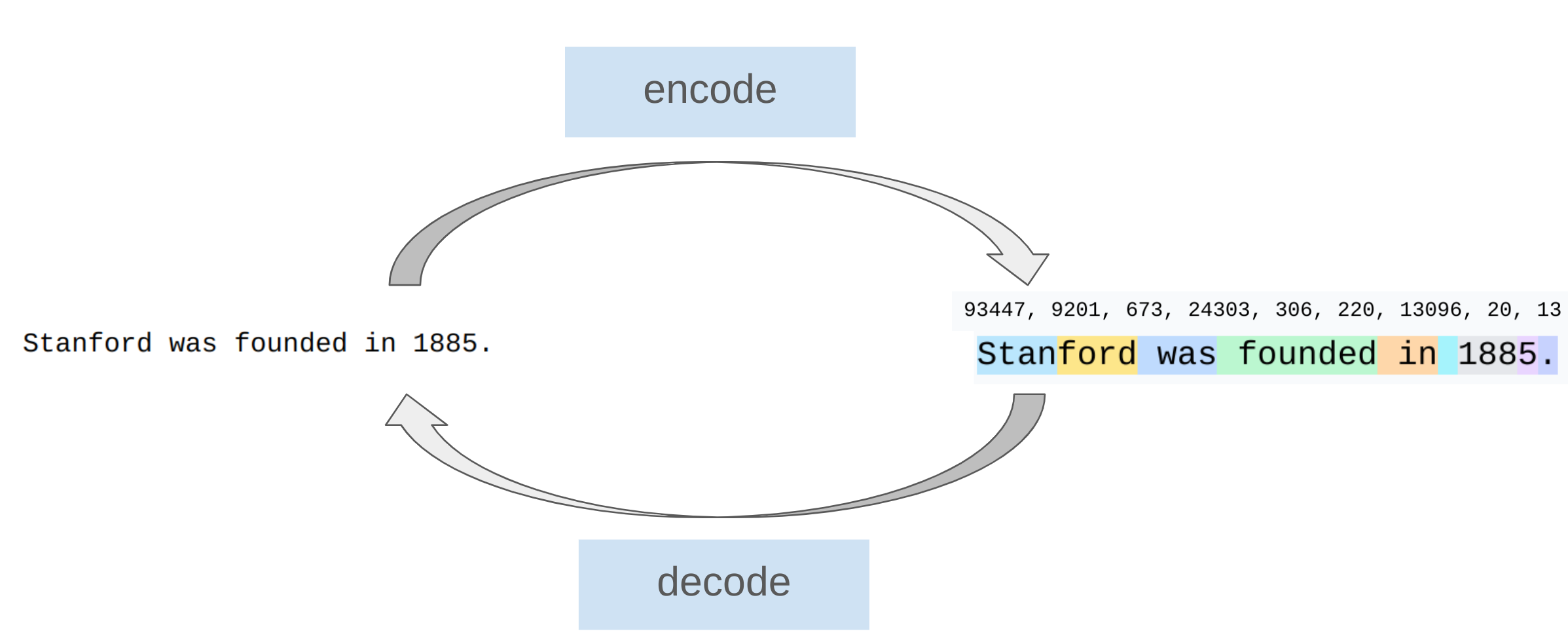
Tokenizer
Tokenizers convert between strings and sequences of integers (tokens)
最好就是直接用bytes,可惜现在硬件水平不得行啊
Character-Based tokenization
class CharacterTokenizer(Tokenizer):
"""Represent a string as a sequence of Unicode code points."""
def encode(self, string: str) -> list[int]:
return list(map(ord, string))
def decode(self, indices: list[int]) -> str:
return "".join(map(chr, indices))
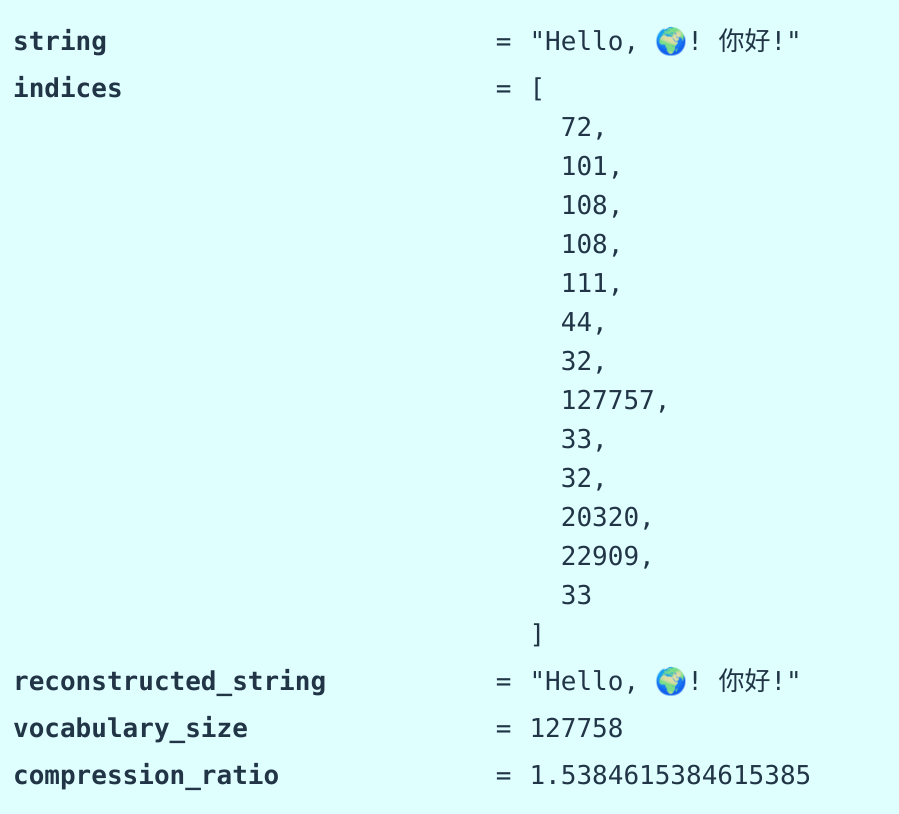
缺点:
- 一个字符一个坑,词表太大了
- 很多字符用的很少,比较罕见
Byte-based tokenization
class ByteTokenizer(Tokenizer):
"""Represent a string as a sequence of bytes."""
def encode(self, string: str) -> list[int]:
string_bytes = string.encode("utf-8") # @inspect string_bytes
indices = list(map(int, string_bytes)) # @inspect indices
return indices
def decode(self, indices: list[int]) -> str:
string_bytes = bytes(indices) # @inspect string_bytes
string = string_bytes.decode("utf-8") # @inspect string
return string
用字节表示,也就是一个字符可以用一个或者多个字节表示
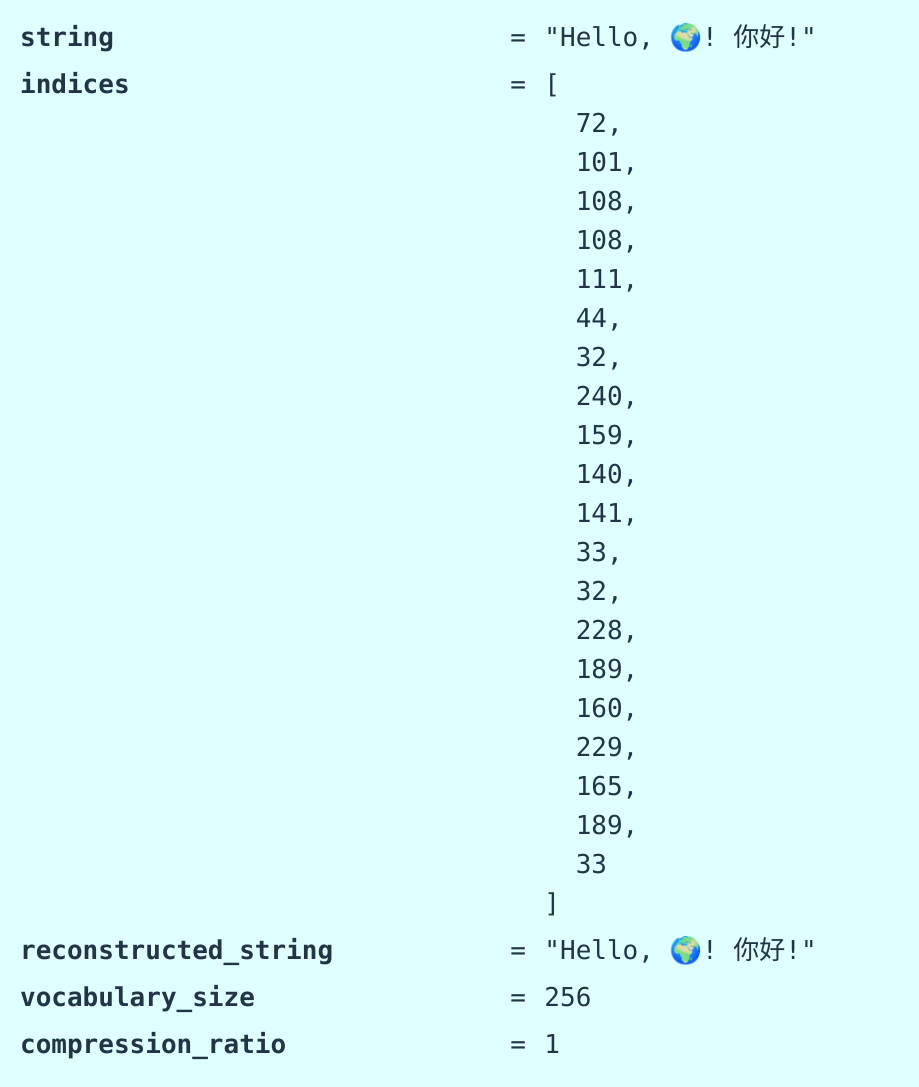
缺点:
- 压缩比是1,生成的序列超级长
Word-based tokenization
正则匹配一个单词一个坑

缺点:
- 词表无限大了要,网络造梗这么快,船是新词啊
- 有些单词基本不用(哎呦,很屌哦!那我问你这话模型能讲出来?)
好处:
- 有的,兄弟,有的,压缩比高啊
Byte Pair Encoding (BPE)
ok,核心来力!
- 基本思路:使用原始文本对分词器进行训练,以自动确定词汇表。
- 直观理解:常见的字符序列由单个令牌表示,罕见的序列由多个令牌表示。
GPT-2 论文采用基于单词的分词方法将文本分解为初始段落,并针对每个段落运行原始的 BPE 算法。
概述:以每个字节作为令牌开始,并依次合并最常见的相邻令牌对。
def merge(indices: list[int], pair: tuple[int, int], new_index: int) -> list[int]: # @inspect indices, @inspect pair, @inspect new_index
"""Return `indices`, but with all instances of `pair` replaced with `new_index`."""
new_indices = [] # @inspect new_indices
i = 0 # @inspect i
while i < len(indices):
if i + 1 < len(indices) and indices[i] == pair[0] and indices[i + 1] == pair[1]:
new_indices.append(new_index)
i += 2
else:
new_indices.append(indices[i])
i += 1
return new_indices
def train_bpe(string: str, num_merges: int) -> BPETokenizerParams: # @inspect string, @inspect num_merges
# Start with the list of bytes of string.
indices = list(map(int, string.encode("utf-8"))) # @inspect indices
merges: dict[tuple[int, int], int] = {} # index1, index2 => merged index
vocab: dict[int, bytes] = {x: bytes([x]) for x in range(256)} # index -> bytes
for i in range(num_merges):
# Count the number of occurrences of each pair of tokens
counts = defaultdict(int)
for index1, index2 in zip(indices, indices[1:]): # For each adjacent pair
counts[(index1, index2)] += 1 # @inspect counts
# Find the most common pair.
pair = max(counts, key=counts.get) # @inspect pair
index1, index2 = pair
# Merge that pair.
new_index = 256 + i # @inspect new_index
merges[pair] = new_index # @inspect merges
vocab[new_index] = vocab[index1] + vocab[index2] # @inspect vocab
indices = merge(indices, pair, new_index) # @inspect indices
return BPETokenizerParams(vocab=vocab, merges=merges)
传入
string = "the cat in the hat" # @inspect string
params = train_bpe(string, num_merges=3)
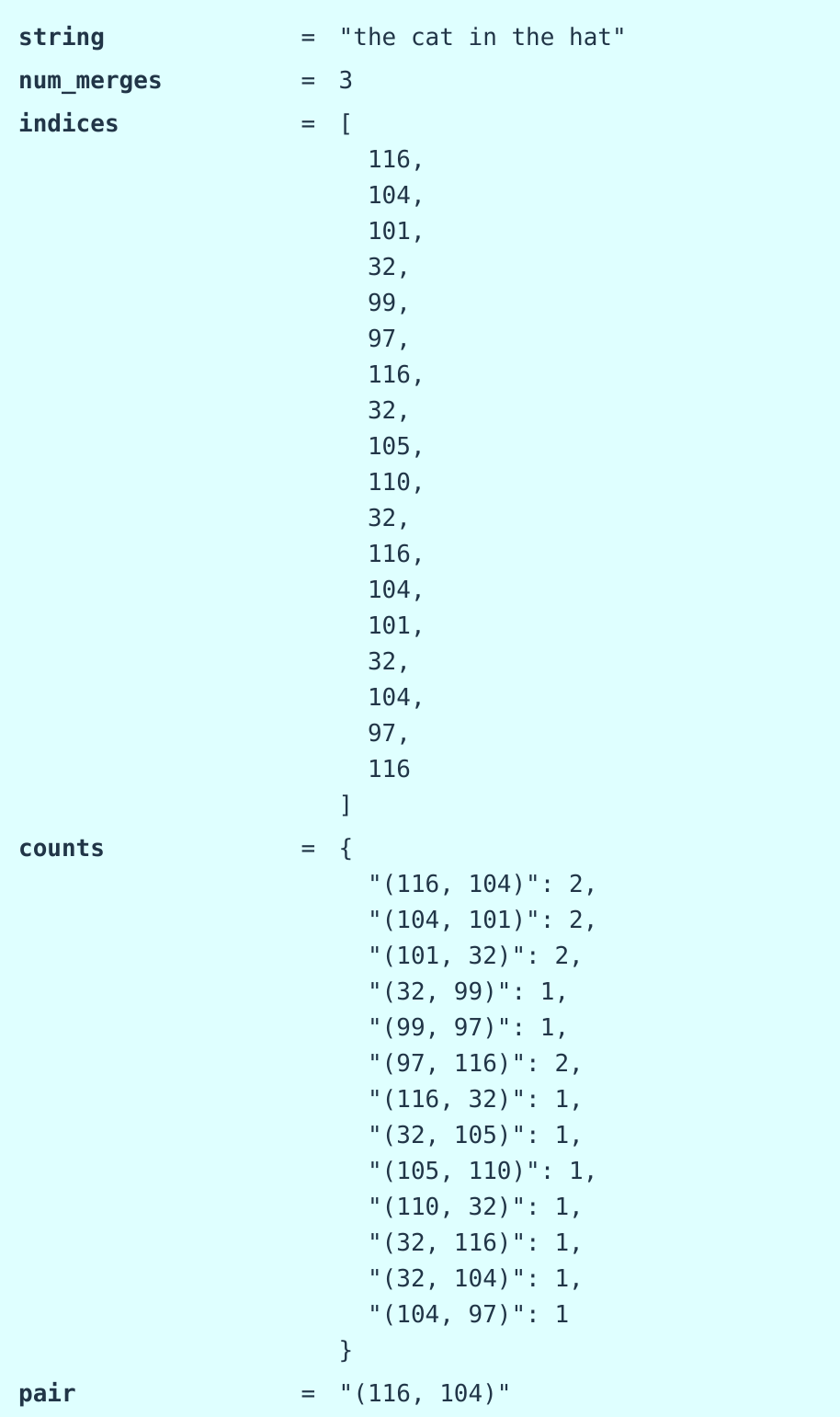
统计相邻的最大次数(有点像协同过滤里面共现矩阵啊)
找共现次数最多的去合并成一个新的index

这里最好去实操一下url
比如原来词表大小5个
| index | char |
|---|---|
| 0 | 哈 |
| 1 | 基 |
| 2 | 咪 |
| 3 | 曼 |
| 4 | 波 |
我说一句话:“哈哈基咪哈基咪曼波”
排列是:001201234
12共现了两次
那我就把词表加一个变成下面这样,后面出现基咪就用5表示
| index | char |
|---|---|
| 0 | 哈 |
| 1 | 基 |
| 2 | 咪 |
| 3 | 曼 |
| 4 | 波 |
| 5 | 基咪 |
排列变成:0050534
序列就变短了
再来一次
就是05合并变成
| index | char |
|---|---|
| 0 | 哈 |
| 1 | 基 |
| 2 | 咪 |
| 3 | 曼 |
| 4 | 波 |
| 5 | 基咪 |
| 6 | 哈基咪 |
排列变成:06634这样
AI解释: 在 BPE 的每一次“选最高频 pair → 合并 → 更新计数”循环里,只合并一条 pair 即可,哪怕同时有多条 pair 的频率并列第一。 原因:
- 合并一条后,整个语料中的 token 序列就变了,很多 pair 会被拆散或新生成,原来并列的那些 8 次 pair 的频率会立即改变;
- 如果一次合并多条,它们可能互相影响(例如两条 pair 共享 token),导致实际频率与统计值不符。
class BPETokenizer(Tokenizer):
"""BPE tokenizer given a set of merges and a vocabulary."""
def __init__(self, params: BPETokenizerParams):
self.params = params
def encode(self, string: str) -> list[int]:
indices = list(map(int, string.encode("utf-8"))) # @inspect indices
# Note: this is a very slow implementation
for pair, new_index in self.params.merges.items(): # @inspect pair, @inspect new_index
indices = merge(indices, pair, new_index)
return indices
def decode(self, indices: list[int]) -> str:
bytes_list = list(map(self.params.vocab.get, indices)) # @inspect bytes_list
string = b"".join(bytes_list).decode("utf-8") # @inspect string
return string
最终的token词表就会增加,下面的258就是新加的th
